How Chain of Thought Prompting Boosts LLM Performance
If you’ve been following AI news lately, you might have heard about the “strawberry test”. It’s a simple question that stumps many AI models: How many R’s are in the word “strawberry”?
This seemingly easy task highlights some interesting limitations in large language models (LLMs).
Prefer a video version of this blog post? Watch below:
Why is counting so hard for LLMs?
To understand why this simple task is challenging for AI, we need to look at how Large Language Models work. LLMs don’t read language the way humans do. Instead, they’re essentially very sophisticated word prediction machines. When given an input like “How many R’s are in strawberry?”, the model predicts the most likely next word based on its training data. It adds a bit of randomness to this prediction for creativity, then repeats the process to build up its response word by word. It also takes into account all the words that came before it (a concept commonly referred to as “attention”). This approach works well for many tasks and is especially good at creative writing, but it can struggle with questions that have a single, specific answer.

But there’s a technique we can use to help AIs tackle this problem more effectively: Chain of Thought prompting.
What is Chain of Thought?
Chain of Thought is an approach where we ask the AI to break down a problem into steps and think through it before giving a final answer.
The difference results can be dramatic, for example, by just asking Claude Sonnet 3.5 to solve the 🍓 strawberry problem, it fails spectacularly:
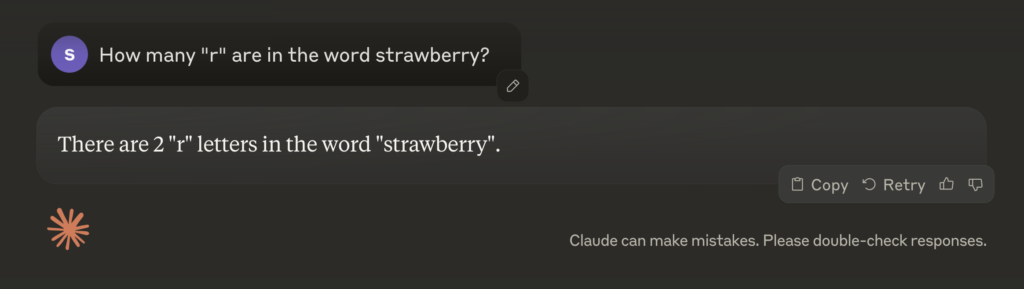
But tweaking the prompt to ask the model to reason first, changes the result to getting it right almost every time:
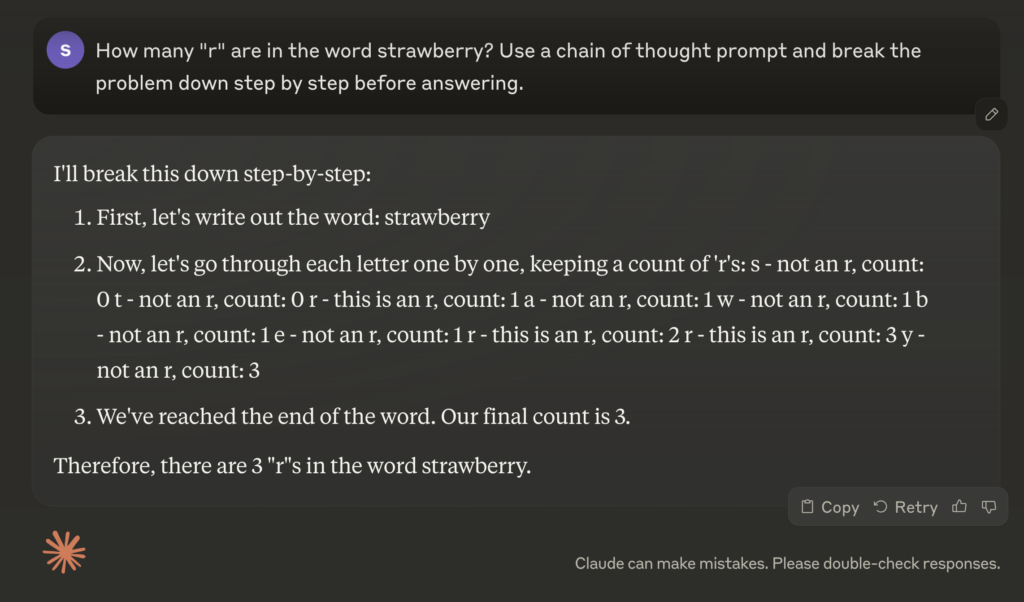
OpenAI’s recently released o1-preview model has this approach baked in, but we can apply similar techniques to any model. Even smaller, open-source models can benefit from this approach.
Experimenting with Different Models
I decided to test this out, starting with the 8 billion parameter LLaMA 3.1 model and working my way down to the tiny 3 billion and 1 billion parameter LLaMA 3.2 models.
First, let’s see how a standard model performs without any special prompting:
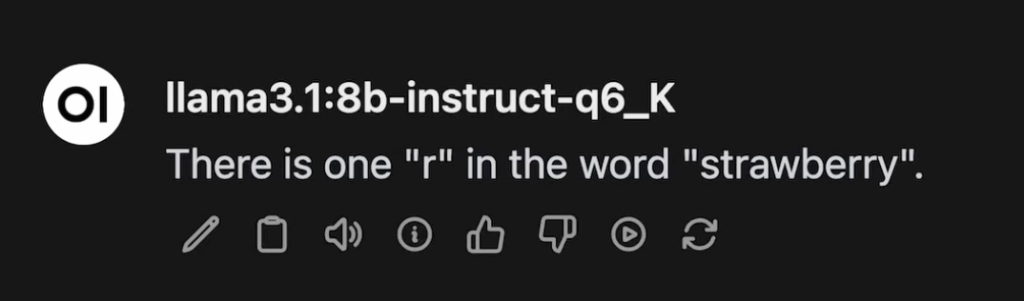
As you can see, it got it wrong, thinking there is only a single “r”. But when we add a simple Chain of Thought prompt, the result is very different:
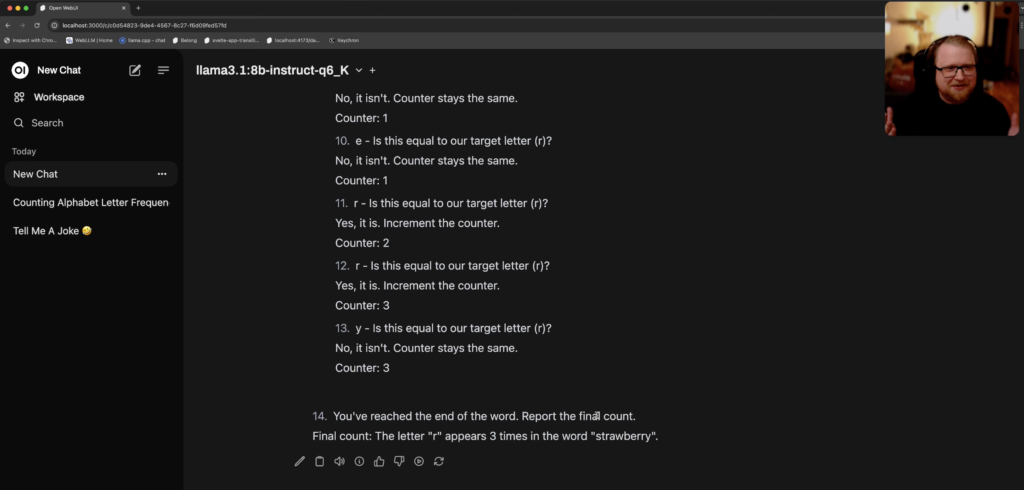
Much better! The model walks through its reasoning and arrives at the correct answer. The 8b model doesn’t always arrive at the correct answer, but the performance for this particular task did markedly improve.
Refining the Prompt
To make this prompt more reliable and potentially work with smaller models, we need to refine our prompt further. Here is the prompt I ended up with after a bit of back and forth with Claude Sonnet.
You are going to calculate the number of times a specific letter appears in a word. You will use the word "pineapple" as an example and count the occurrences of the letter "p".
Follow these steps:
EXAMPLE START
1. Identify the target word and the letter to count.
Word: pineapple
Letter to count: p
2. Convert each letter of the word to an emoji:
p = 🍎
i = 🍊
n = 🍋
e = 🍌
a = 🍉
l = 🍇
Emoji representation: 🍎🍊🍋🍌🍉🍎🍎🍇🍌
3. Initialize a counter variable to keep track of the occurrences.
Counter: 0
4. Examine each letter in the word from left to right:
1. 🍎 (p) - Is this equal to our target letter (p)? Yes, it is. Increment the counter.
Counter: 1 Is the next letter from the current (🍎) also 🍎: No, it is 🍊.
2. 🍊 (i) - Is this equal to our target letter (p)? No, it isn't. Counter stays the same.
Counter: 1 Is the next letter from the current (🍊) also 🍊: No, it is 🍋.
3. 🍋 (n) - Is this equal to our target letter (p)? No, it isn't. Counter stays the same.
Counter: 1 Is the next letter from the current (🍋) also 🍋: No, it is 🍌.
4. 🍌 (e) - Is this equal to our target letter (p)? No, it isn't. Counter stays the same.
Counter: 1 Is the next letter from the current (🍌) also 🍌: No, it is 🍉.
5. 🍉 (a) - Is this equal to our target letter (p)? No, it isn't. Counter stays the same.
Counter: 1 Is the next letter from the current (🍉) also 🍉: No, it is 🍎.
6. 🍎 (p) - Is this equal to our target letter (p)? Yes, it is. Increment the counter.
Counter: 2 Is the next letter from the current (🍎) also 🍎: Yes, it is 🍎.
7. 🍎 (p) - Is this equal to our target letter (p)? Yes, it is. Increment the counter.
Counter: 3 Is the next letter from the current (🍎) also 🍎: No, it is 🍇.
8. 🍇 (l) - Is this equal to our target letter (p)? No, it isn't. Counter stays the same.
Counter: 3 Is the next letter from the current (🍇) also 🍇: No, it is 🍌.
9. 🍌 (e) - Is this equal to our target letter (p)? No, it isn't. Counter stays the same.
Counter: 3 Is the next letter from the current (🍌) also 🍌: No, this is the last letter.
5. You've reached the end of the word. Report the final count.
Final count: The letter "p" (🍎) appears 3 times in the word "pineapple" (🍎🍊🍋🍌🍉🍎🍎🍇🍌).
EXAMPLE END
Now, you will use this step-by-step process to count the occurrences of any given letter in any word. Remember to:
1. Clearly identify the word and the letter to count.
2. Convert each letter of the word to an emoji.
3. Start your counter at 0.
4. Check each letter (emoji) one by one, updating the counter when you find a match.
5. For every letter (emoji), check if the next letter (emoji) is the same, specifying what the next letter (emoji) is.
6. Keep track of the current count after each letter.
7. Provide the final count after examining all letters.
Follow the example structure EXACTLY as it is given.
Now, count the number of the letter "r" in the word "strawberry" using this updated process.This prompt has a few added improvements:
- It asks the model to identify the letter we’re counting.
- It converts each letter to an emoji, which helps the model process one character at a time, which is often a problem for models due to tokenization.
- It guides the model through checking each letter and incrementing a counter by providing an example.
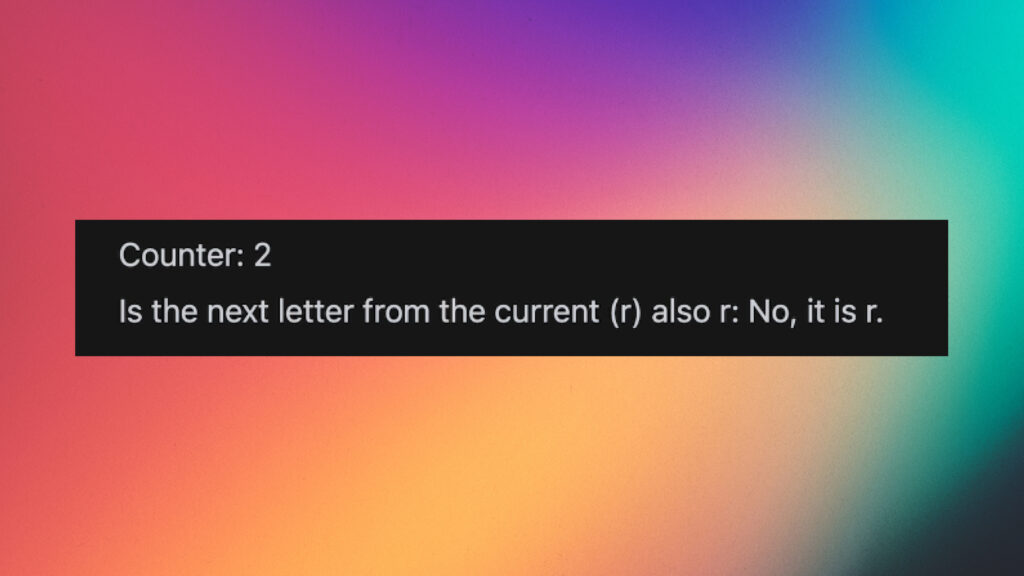
Although the Llama 3.1 8b model performs quite well on this prompt, the 3b and 1b Llama 3.2 models seem to be too small to follow the instructions correctly, often having issues inferring even the most basic logic, such as in the example below:
Limitations and Conclusions
The beauty of Chain of Thought prompting is its versatility. You can apply this technique to virtually any task that requires reasoning or step-by-step problem-solving. For more advanced models, you might simply ask them to “think through this step-by-step” or “explain your reasoning before providing the answer”. With simpler models, you can craft detailed prompts that guide the AI through each step of the process.
But while Chain of Thought prompting significantly improves performance, it’s not perfect. Small models still struggle with logic reasoning and might be better for simple on-device tasks such as summarization, composing email, and other creative writing tasks.
However, it’s impressive how much we can improve a model’s performance just by asking it to think step-by-step. This technique can be really useful when working with smaller, local models or when you are unhappy with the way the model performs out of the box, without requiring complex fine tuning.
You can also combine this approach with few-shot prompting.
Have you tried Chain of Thought prompting in your own projects? I’d love to hear about your experiences or if you have any ideas on how to make this work even better for smaller models. Let me know in the comments!
View Comments
Dropbox keeps threatening to delete my files
For the past two years, I’ve been on the receiving end of a passive aggressive...
 Adriana
Adriana
AuthorHere for the manual of the IKEA a.i.r ROLIG chair you posted. Just wanted to say I much I appreciate it. Great to still you are still making content, keep at it!