How and why I built an MCP server for Svelte
If you’re using Svelte with coding assistants, you know that these assistants aren’t always aware of the latest features in Svelte 5 and SvelteKit. They’ll suggest outdated patterns, mix up the old reactive syntax with the new runes system, or simply hallucinate syntax that doesn’t exist. These problems have made LLM assistants less useful in Svelte and SvelteKit projects – so I decided to set out and build an MCP (Model Context Protocol) server that gives AI assistants direct access to the latest Svelte documentation.
Demo: What can it actually do?
Here’s a short video I recorded demonstrating some of the features such as documentation searching, resources and the dedicated “Svelte Developer” prompt:
Why do we need a Svelte MCP in the first place?
Svelte 5 introduced big syntax changes in order to improve the language. The old reactivity syntax like let count = 0; $: doubled = count * 2 is gone, replaced by runes: let count = $state(0); let doubled = $derived(count * 2). Event handlers changed from on:click to onclick. SvelteKit also received new features like Remote Functions. The list of changes goes on.
Most AI models were trained before these changes landed. When you ask them for help, they confidently give you old code. Even worse, they sometimes mix Svelte 4 and Svelte 5 syntax in the same example, creating code that won’t run at all.
How MCPs fill the knowledge gap
MCP (Model Context Protocol) is a standard from Anthropic that lets AI assistants connect to external tools and data sources. Instead of relying solely on training data, the assistant can fetch information on-demand. It gives AI assistants the ability to look things up when they need to, just like you would by checking out the official documentation.
The MCP server I built serves the latest Svelte and SvelteKit documentation directly from the official GitHub repository. The assistant can query for specific topics, list available sections, or pull in entire documentation sets based on the task at hand.
What does MCP as a protocol offer?

MCP provides several primitives for extending AI assistants.
- Tools are functions the assistant can call. We provide list_sections which list all documentation sections that are available, and get_documentation which returns one or more documentation sections that the LLM asks for.
- Resources are read-only data sources the assistant can browse through – each documentation section becomes a resource accessible via URIs like
svelte-llm://docs/svelte/runes. We provide every markdown file from the Svelte and SvelteKit documentation as a separate resource. - Prompts are reusable templates that inject specific context – We use these to provide curated documentation sets like “svelte-core” or “sveltekit-production” as well as a “Svelte Developer” preset that provides a customized prompt for Svelte and SvelteKit tasks.
(There are more primitives such as Completions and client-specific features like Sampling and Elicitation, but these were not used.)
As we glean from the above, the big MCP benefit is that instead of dumping entire documentation sets into context (aka. llms.txt files), the assistant can intelligently fetch what’s needed.
What does the code actually look like?
One of the things that annoyed me when reading about MCP is that there’s so much prose – why it’s good, why you should use it, why it’s better than a REST API, but the code samples were few and far between. So I’m here to say working on an MCP works pretty much like your average REST API from a programming standpoint. Let’s build a simple MCP tool called roll_die that returns the result of an N-side die roll:
server.tool(
'roll_die',
'Rolls a die with a specified number of sides',
{
sides: z
.number()
.int()
.min(2)
.default(6)
.describe('Number of sides on the die (defaults to 6)')
},
async ({ sides }: { sides: number }) => {
const result = Math.floor(Math.random() * sides) + 1
return {
content: [
{
type: 'text' as const,
text: `🎲 Rolled a d${sides}: **${result}**`
}
]
}
}
)I omitted the MCP initialization code for brevity, but you can see it’s the familiar “register a route/tool and a callback handler” pattern. If you want to see the actual implementation of the Svelte MCP tools you can find them on GitHub!
How the Svelte MCP works
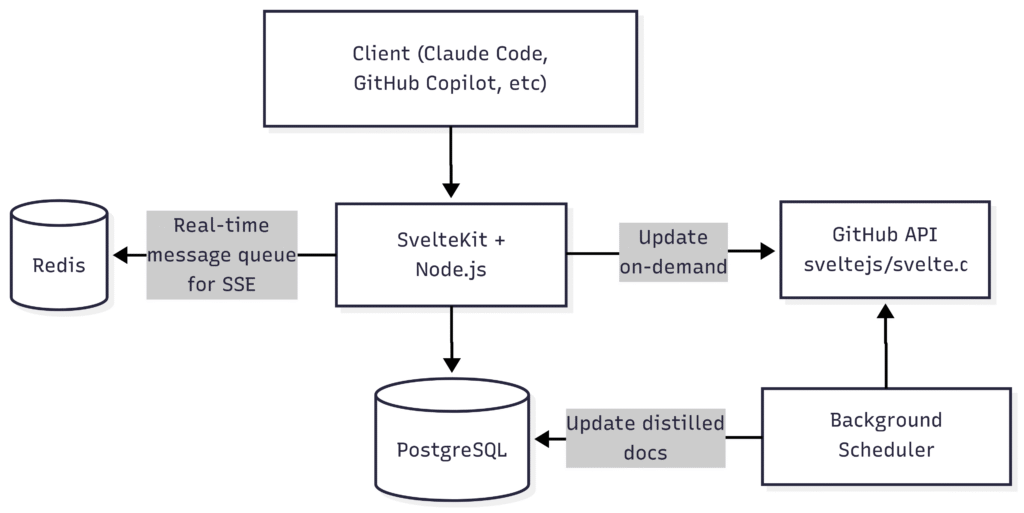
Every hour, a scheduled job fetches the latest documentation from the official Svelte GitHub repository. The documentation markdown files get processed, metadata is extracted, and everything is stored in PostgreSQL. When an AI assistant needs documentation, it connects to the MCP server which queries the database. Of course, we use SvelteKit itself for providing the website and MCP functionality, and mcp-adapter to handle the MCP protocol.
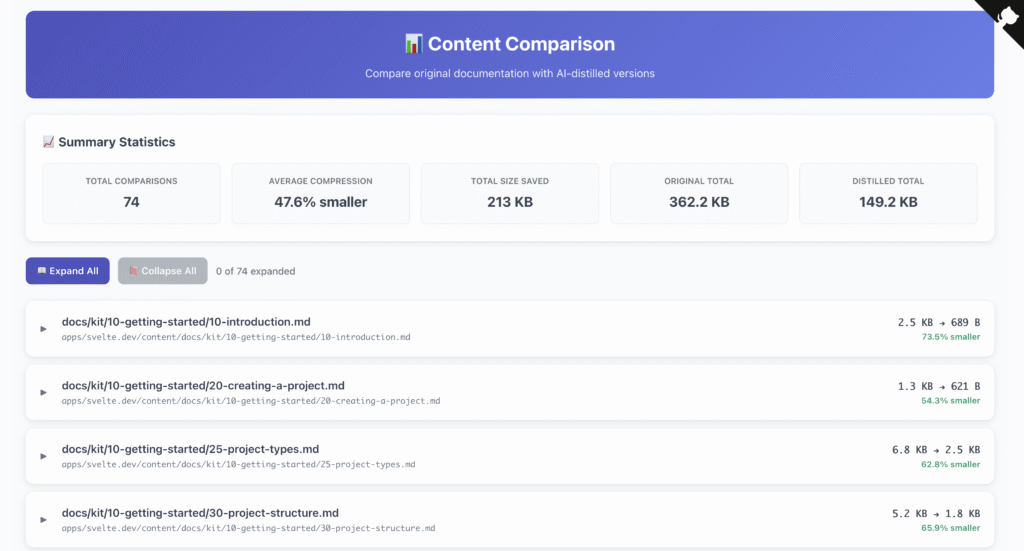
Distilling documentation to save on context
The complete Svelte and SvelteKit documentation is about 800KB of text. That’s hundreds of thousands of tokens, which eat into or completely exhaust the LLMs context length! LLMs have also been shown to become “unfocused” as context grows. To combat this, I built a feature that uses an LLM to create condensed versions of the docs.
The distillation process strips out redundant content while keeping code examples and key concepts. The result is about ~50% smaller but still contains the essential information.
You can compare the before/after of the distillation process yourself by visiting this interactive comparison tool! The process is performed server-side where the service is hosted, so it only needs to be done once, or after significant documentation updates are made.
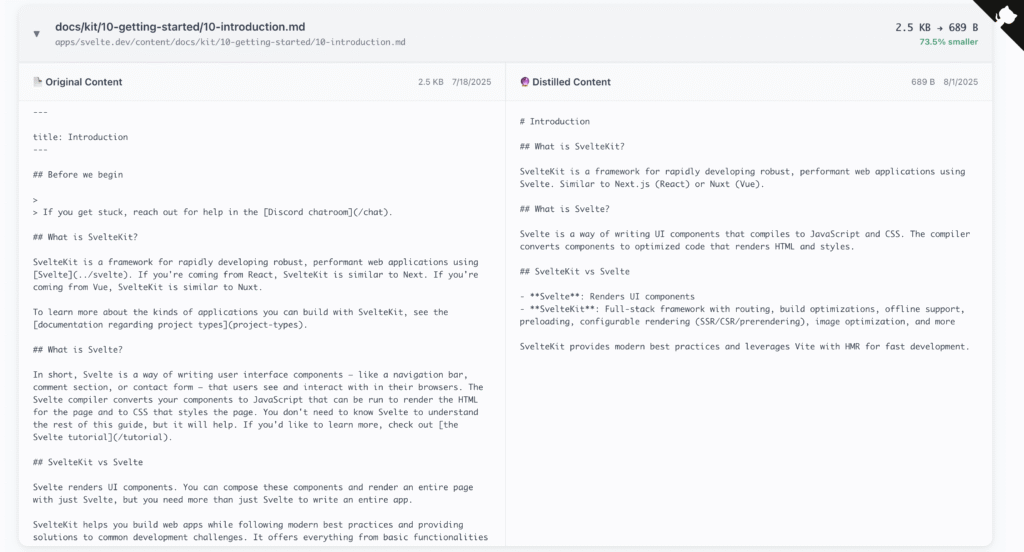
The distilled versions are generated automatically and stored alongside the originals. For the dedicated resource presets in the MCP (svelte-core, svelte-advanced, svelte-complete and so on) I decided to use these distilled presets rather than the full documentation to save on context space.
The fragmented MCP client ecosystem
There are three different protocols for interfacing with MCP servers – stdio, SSE, and Streamable HTTP – and not all clients support all of them.
Stdio runs locally (typically it’s just a npx or Python command) and can access local resources such as read/write your files, but you also have to install it on every machine.
SSE and Streamable HTTP are remote protocols – you just point to a URL and they work. Streamable is also easier to implement than SSE since SSE for technical reasons requires a queue (Redis in our case) to pass messages between the server and client.
For example, to add the Svelte MCP to Claude Code, you just need to type this one command into your terminal:
claude mcp add --transport http --scope project svelte-llm https://svelte-llm.stanislav.garden/mcp/mcpAs a side note, even though Anthropic created the MCP protocol, Claude Desktop was late to support Streamable HTTP. Until recently, you had to use the SSE protocol when using Claude Desktop. Now, luckily most clients finally support Streamable! But in the end, I ended up supporting both SSE and Streamable HTTP to maximize compatibility with older clients.
Final reflections
Building this MCP was really interesting. I use Svelte daily and having AI assistants that understand the current version saves a lot of time! But more broadly, this project shows we don’t need to wait for AI models to be retrained to get accurate information about rapidly evolving tools. As frameworks and libraries continue to evolve quickly, this kind of real-time documentation access becomes increasingly valuable.
If you work with Svelte and AI coding assistants, you can try it out at svelte-llm.stanislav.garden. The project is open source and contributions are welcome. I’ve got some interesting new features for this MCP planned as well, and I’m speaking with Svelte maintainers about creating an official Svelte MCP as well!
Social Photo by cottonbro studio.
View Comments
Claude Code hooks for simple macOS notifications
I’ve been using Claude Code for a while now, and one thing that always bugged me was...
 Manoj
Manoj
AuthorHello,
Why did you not use a vectorDB and a simple RAG system to store the docs, and then have it extract the relevant parts of the docs for injection as context rather than storing the entire thing in postgres (minified though it may be).
 Stanislav Khromov
Stanislav Khromov
AuthorGreat question! I was playing around with RAG solutions (LlamaIndex) but I couldn’t get it to work well. When I searched for things I would just not get the results I expected. I think semantic search like RAG might not be the best choice for this sort of use case, because for example “How do I build a slider component?” is very far semantically from the associated documentation (eg: reactivity, styles). You can try that question on Context7 and it will also give you unrelated results. In the official Svelte MCP ( https://svelte.dev/docs/mcp/overview ) we are trying some other approaches (like use_cases):
https://github.com/sveltejs/mcp/pull/29
 bellomondo
bellomondo
AuthorGreat work! I would love to see your take on figuring how to setup Claude to produce Svelte/Kit apps in newer models (Sonnet 4.5, Haiku 4.5, Opus 4.1). Since I handcoded everything by myself until five minutes ago (late bloomer), I have been burning tokens on just learning how the thing works, and have a ton of noob questions, like:
– do I create a separate agent for coding in Svelte, or multiple agents, as in backend (Sveltekit-DBs-APIs), and frontend (Svelte 5-Design-UX/UI) experts, combining other docs with each of them?
– what do I do with the svelte-taks prompt? Is it a Skill, an instruction for an agent, or just a prompt to reuse?ti
– do I use Skills for Svelte/Kit at all, since Claude sometimes ignores them without elaborate hooks?
– how different models test on different taks (I’m not rich)?
I’m eagerly awaiting for your updates on the matter, keep up the good work for lazy me. 🙂
 Stanislav Khromov
Stanislav Khromov
AuthorHi Bello. Many good questions, that I will answer in a YouTube video soon. 🙂 But to answer briefly, you don’t need to create any specific agents for Svelte, it’s enough to use the MCP. To use the svelte-task prompt, you can simply type /svelte-task in Claude Code and it will autocomplete it for you, then you add your task, eg “/svelte-task build a pokemon gallery for me.”
For model performance, check out SvelteBench where we test many different models:
https://khromov.github.io/svelte-bench/benchmark-results-merged.html