Building a privacy-friendly, self-hosted application architecture with SvelteKit

This is the second post in a series on building a gratitude journaling app called Appreciation Jar. In the previous post we detailed the process of publishing an iOS and Android app using SvelteKit and Capacitor. Today I wanted to touch on the infrastructure and privacy aspects of the app.
Infrastructure overview
Let’s start with a high level infrastructure diagram and then go into more detail. There’s a lot to unpack but we’re going to go through each part of the diagram one by one! The overarching architectural goal of this app was to be able to run everything “in-house” without relying on third party services, which I managed to accomplish while still having modern fetures like realtime updates, tracking and error monitoring. If you want to try the app before reading this post, you can do so here!
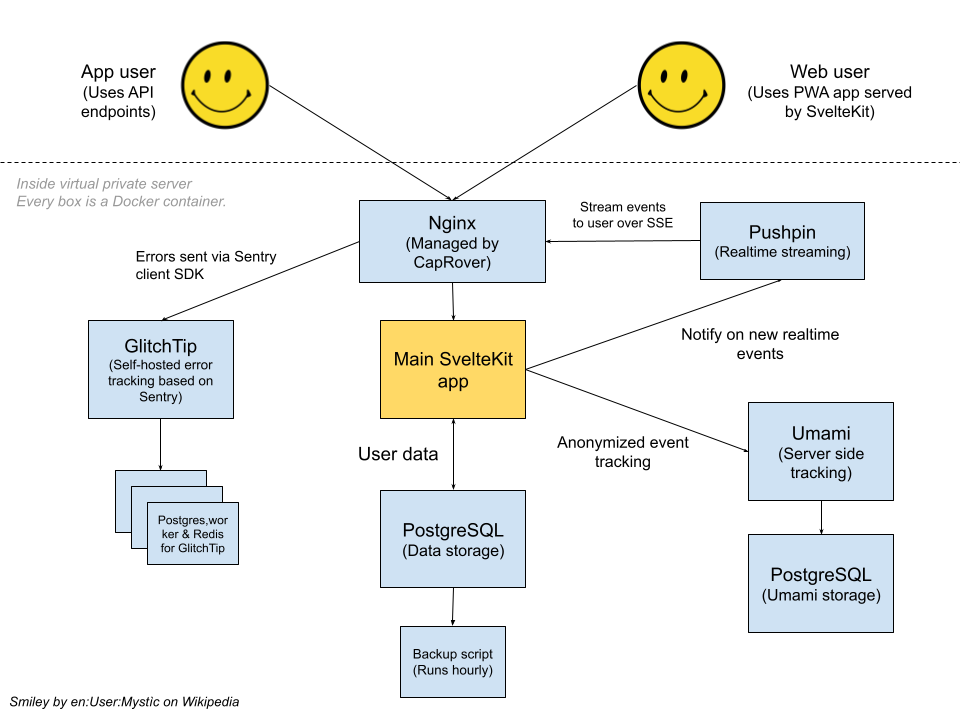
The platform – CapRover
For hosting all of the services I am using CapRover. It’s a wonderfully simple PaaS (platform-as-a-service) that gives you a Heroku-like interface but runs entirely on a Virtual Private Server you control. For automated deploys, GitHub Actions are used. I’ve recorded a tutorial on how to get started with and deploy SvelteKit onto this architecture, so do check it out if this sounds interesting to you by clicking the image below!

Note: It seems the Svelte Society video has some issues with the audio at the end, so if you get stuck you can watch this version of the video where the sound is intact!
The database – PostgreSQL
When you self-host using CapRover, you have a plethora of so-called “One click apps”, that allow you to easily deploy a normal database like MySQL, PostgreSQL or even Microsoft SQL if that’s your cup of tea!
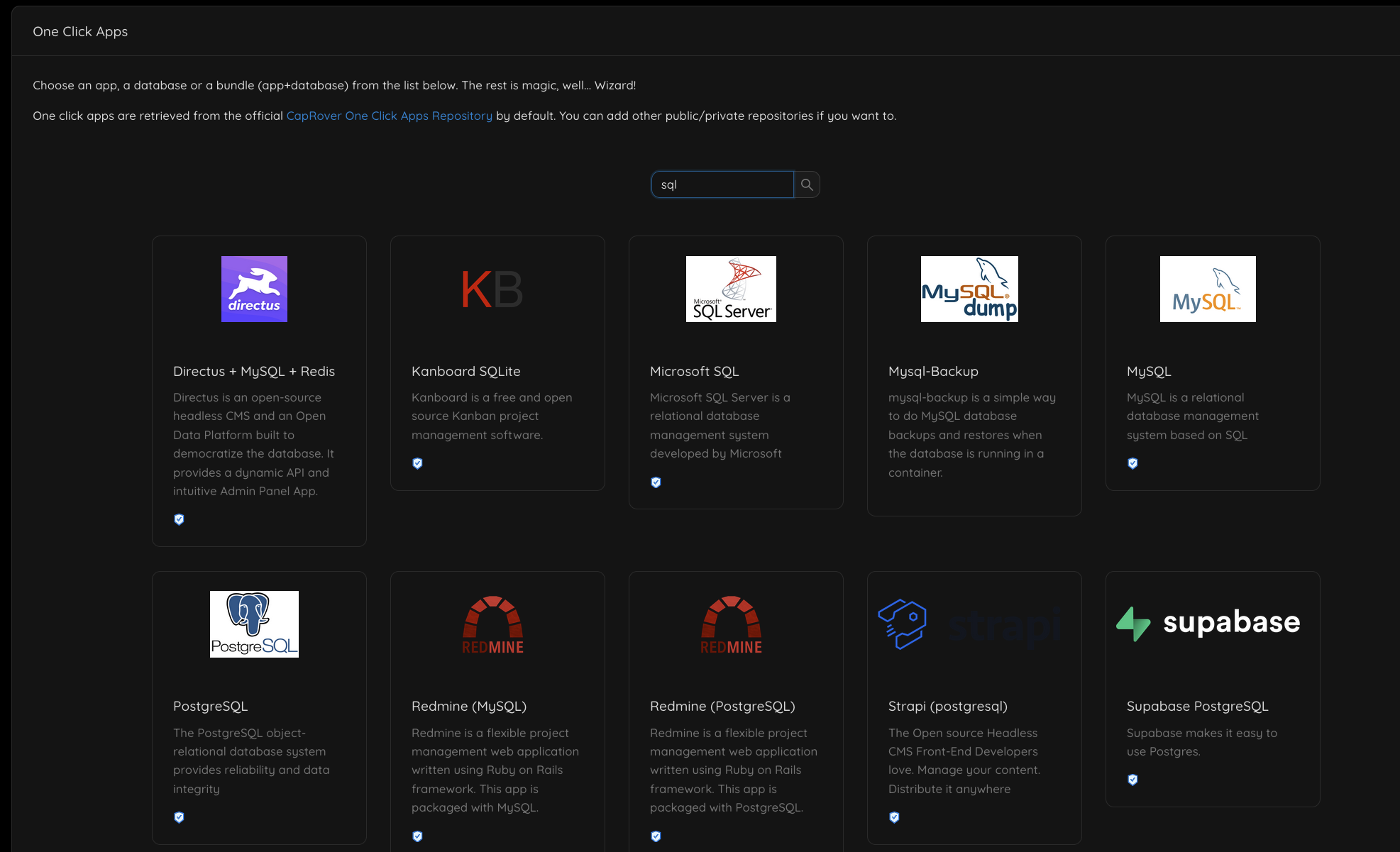
Appreciation Jar is running a standard PostgreSQL instance deployed via the “One Click apps” functionality.
Authentication
For authentication, I wanted to keep things extremely simple, without any third parties. The approach I landed on was:
- When you register as a user, you don’t submit any personal information like your email, phone number or even a password.
- We generate a unique strong password internally for each user upon registration. The generated password is returned to the user and stored in LocalStorage (or
@capacitor/preferenceson iOS/Android – see implementation). - Users are encouraged to save their “recovery key” (which is really just their unique user id + password combination encoded in base36) and restore it later in the app in case they want to switch to a different phone.
- There is some light rate limiting applied to the API courtesy of the excellent sveltekit-rate-limiter package.
This is far from a perfect approach. For example, the onus is on the user to back up their recovery key. On the flip side, it does not require the user to submit any personal data. When it comes to GDPR and privacy, I think the best kind of data is the one you don’t even need to store. 😄
Here are some screenshot of the login system for the curious:
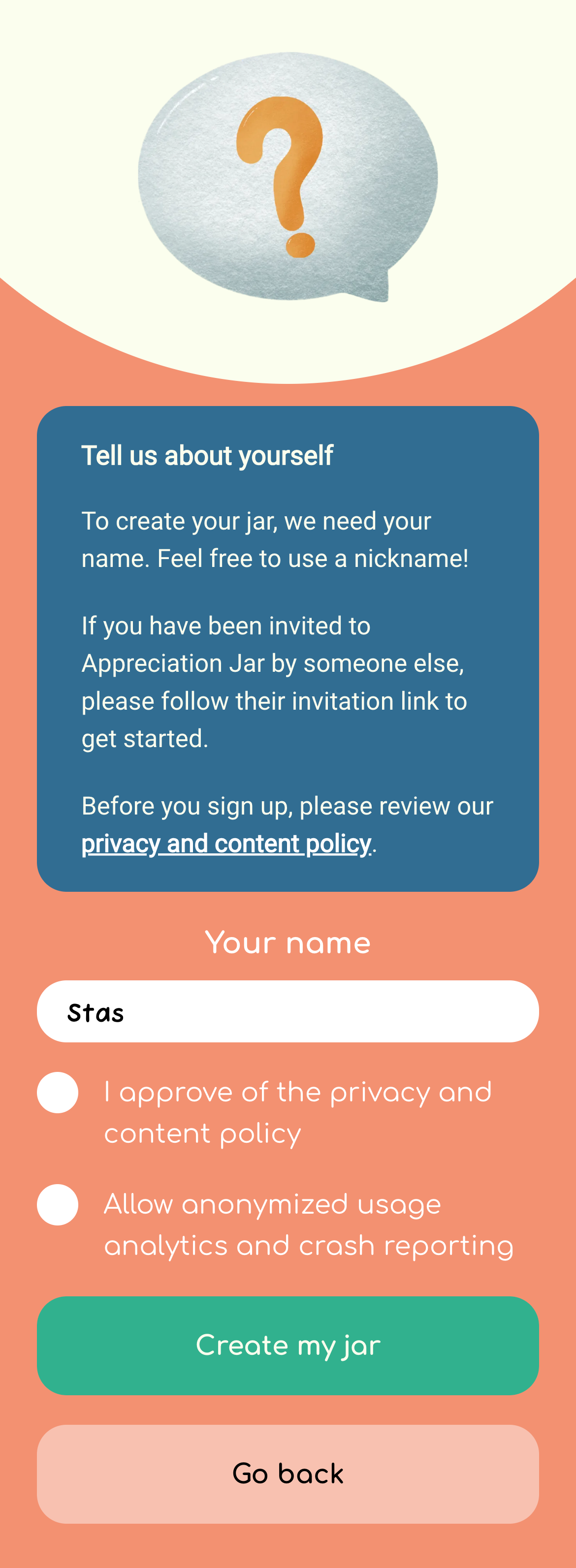
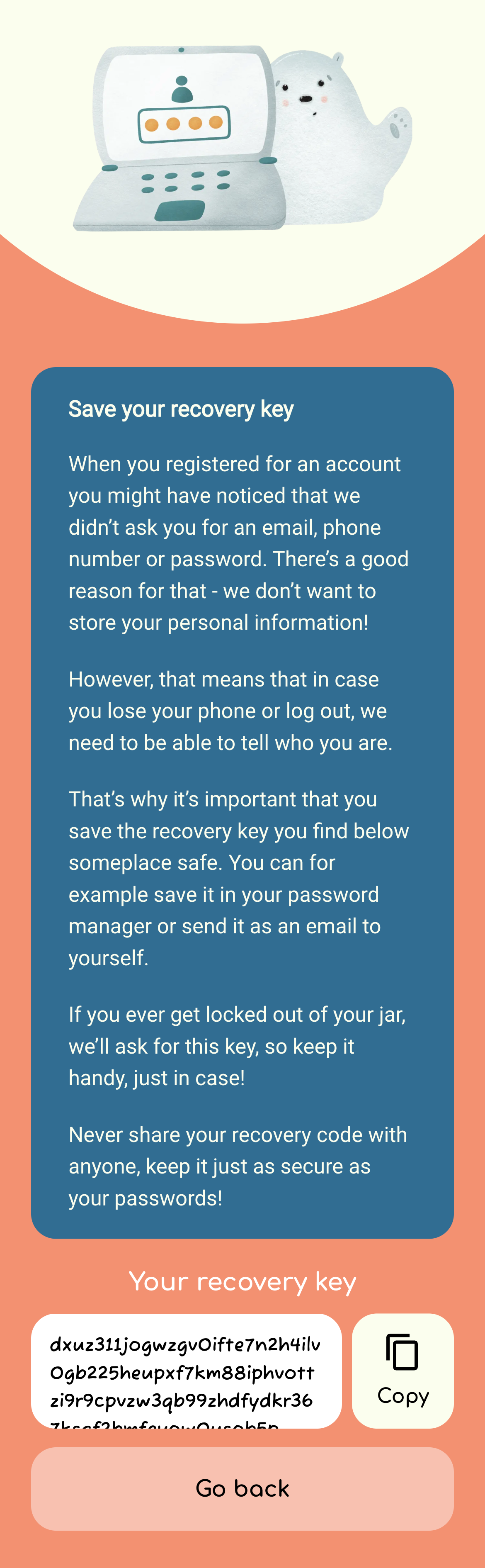
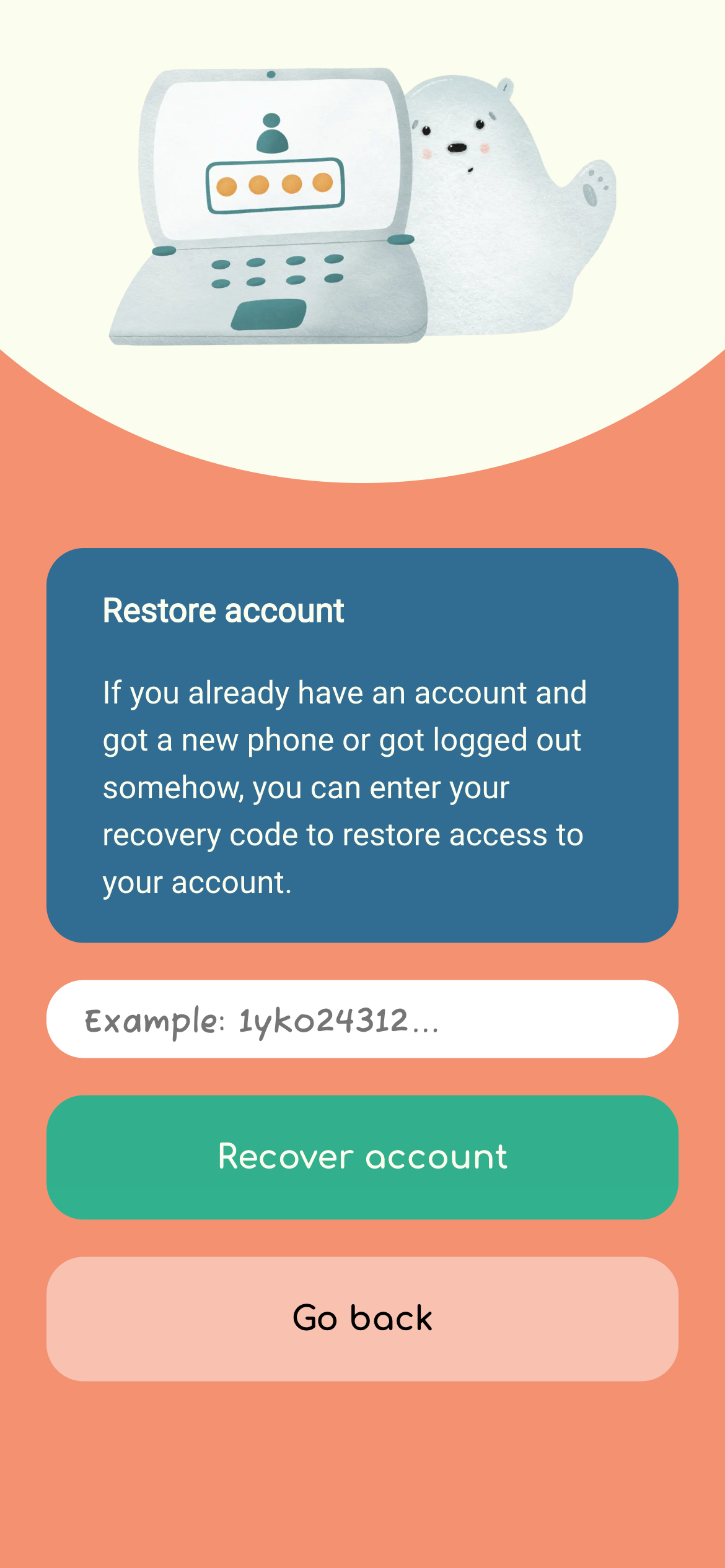
Encryption
Encryption is a particularly difficult topic, and deserves its own blog post – I will only skim the surface here.
Encryption at its core is about privacy, and I believe that privacy can be achived both with and without encryption. For example, by not collecting any user data (other than a nickname) during signup, our app has no idea who our users are. I think this is a pretty good trade-off that still allows you to detect abuse of the platform using automated tooling. It also gives you an option to help users who lost their recovery keys by allowing you to cross check information they provide.
On the other hand, if we choose encryption, things get harder. If we want to truly implement encryption without any security theatre where we hold the users key and can actually unlock the data all along, we need to implement true end-to-end encryption, meaning we cannot have access to the users encryption keys. This means that if a users were to lose their recovery key their data would be inaccessible forever. You would also not be able to detect abuse on the platform because you wouldn’t be able to inspect any data.
What finally tipped the scale in this case was having certain features that need to be accessible through the web browser, like the Dashboard feature in the app, which allows you to put the latest appreciation on something like a smart fridge or a Raspberry Pi. The other thing was that the core of the app is about sharing your messages with other users, which would have involved a rather complex encryption scheme to support adding and removing members. Having this in mind, I chose the privacy-preserving approach instead of end-to-end encryption.
A demo of the dashboard feature.
Analytics with Umami
Analytics is something that can easily become a privacy headache. To get around the issues as much as possible, the strategy I’ve implemented is to self-host the analytics tool Umami (again, via the One click app functionality in CapRover!).
Since I am not really interested in tracking individual users but total aggregates to get an idea of the health of the service, I have also moved the tracking of users from the client side to the server side. This means that the client side has no trackers at all! Instead, we have a small middleware for SvelteKit to track page views and API hits automatically. I’ve assembled the code that sends a tracking request to Umami and the hooks middleware that automatically tracks page views in this gist if you’re interested!
Thanks to this, we can get an overview of user activity without forcing users to load any trackers:
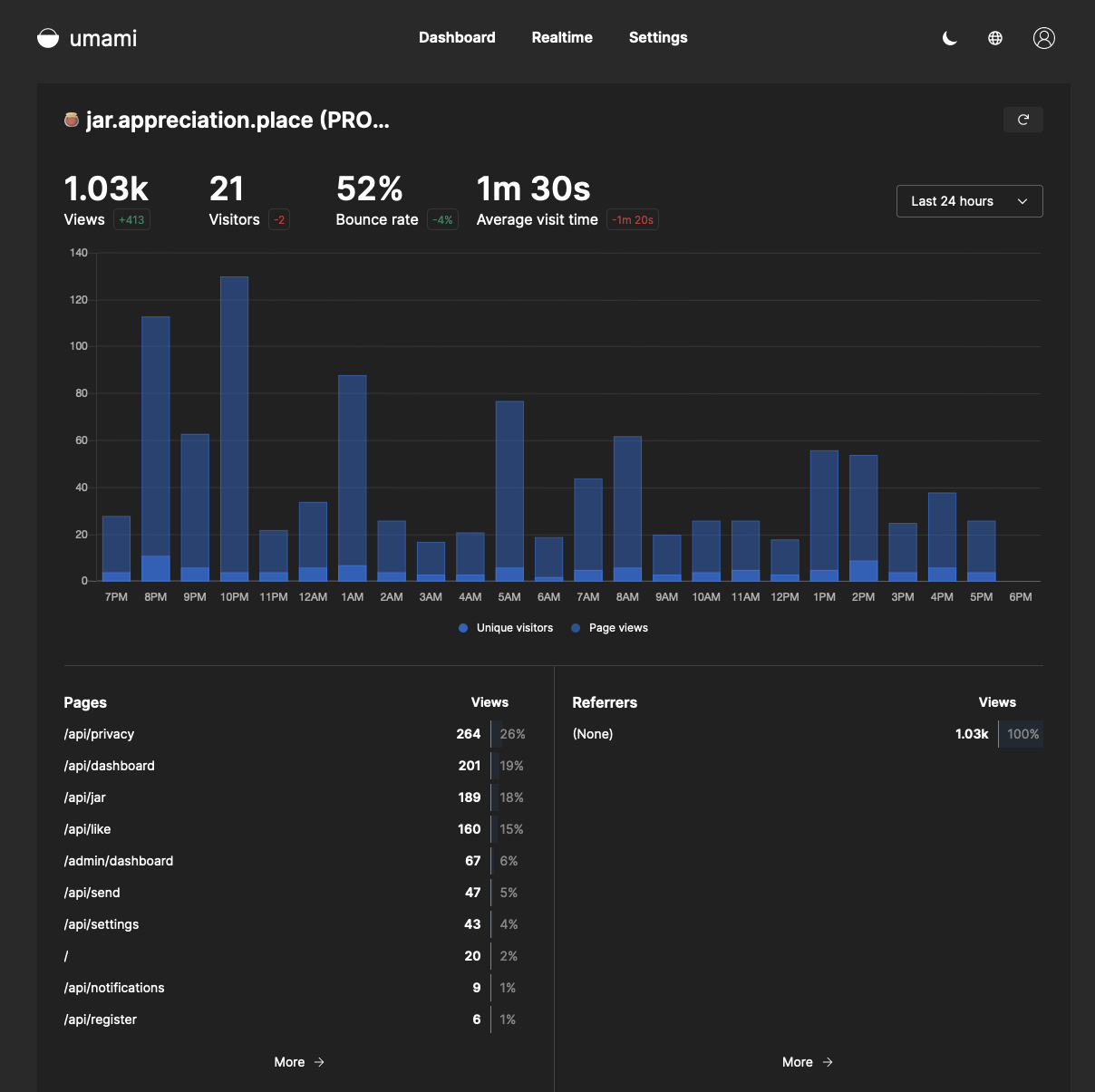
We can also track specific actions in some places, like when a user registers, which can then be plotted on a graph by Umami. For example, here is the tracking call for when a user registers an account:
trackRequest(
'event',
{
url: '/',
event_name: 'user_created'
}
);Again, no user data is sent along with this and it’s done only in a +server.ts endpoint!
And here is how the event dashboard looks:
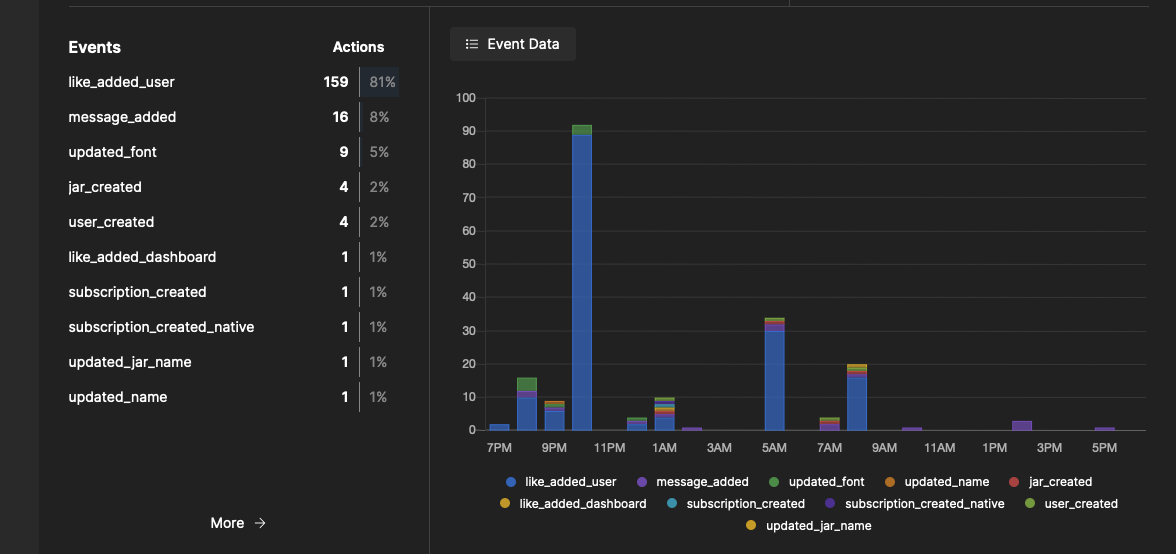
Realtime with Pushpin
For realtime, I used Pushpin with Server Sent Events. (It supports WebSocket as well).
What I really liked about Pushpin is that you can run it as a single self-hosted Docker container and it has a unique architecture where it acts as a proxy on top of your service. I advise you to read their documentation to figure out exactly what this entails, but what it means in practice is that all the authentication and data fetching is handled by the SvelteKit app – Pushpin is just a dumb stateless box that makes sure that users receive updated data in realtime!
With realtime we can do fun things like syncing data across devices without any third party services, here’s a demo:
Error monitoring with GlitchTip
GlitchTip is a very cool self-hosted monitoring service. The reason it’s cool is because it’s compatible with the Sentry client SDK! After setting up GlitchTip from the one-click app in CapRover (notice a patter? 😄) we initialize it in our SvelteKit app using:
import Sentry from '@sentry/svelte';
Sentry.init({
dsn: 'https://123456@example.com/1',
integrations: [new SentryTracing.BrowserTracing()],
tracesSampleRate: 1.0
});..and we’re pretty much done! Now we get a nice dashboard where we can check errors users are experiencing in realtime:
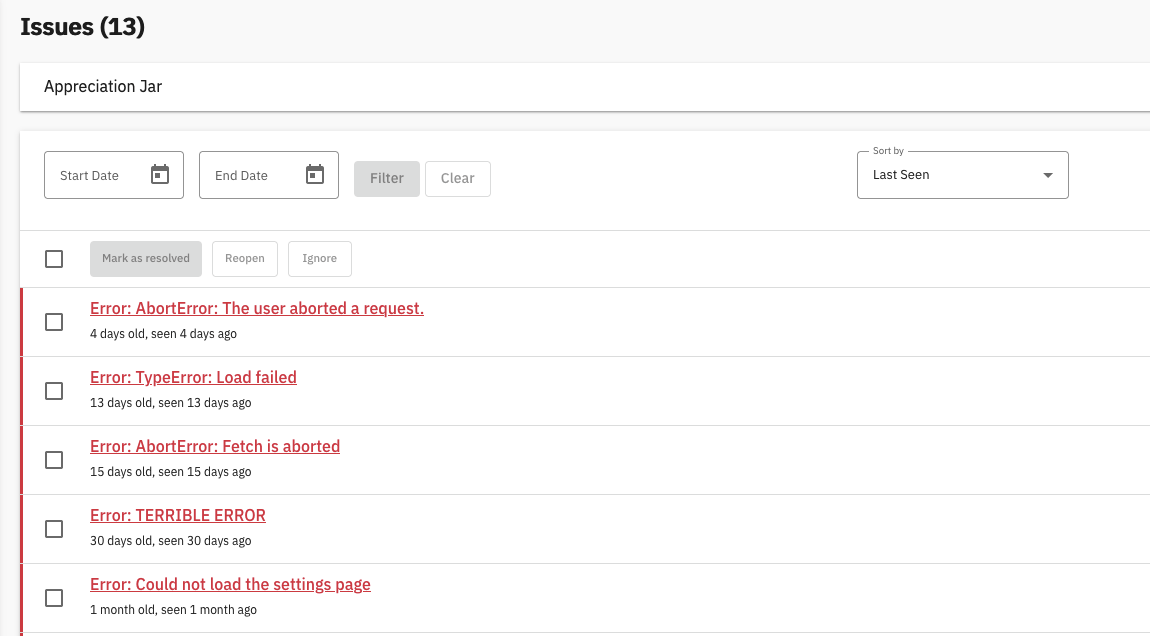
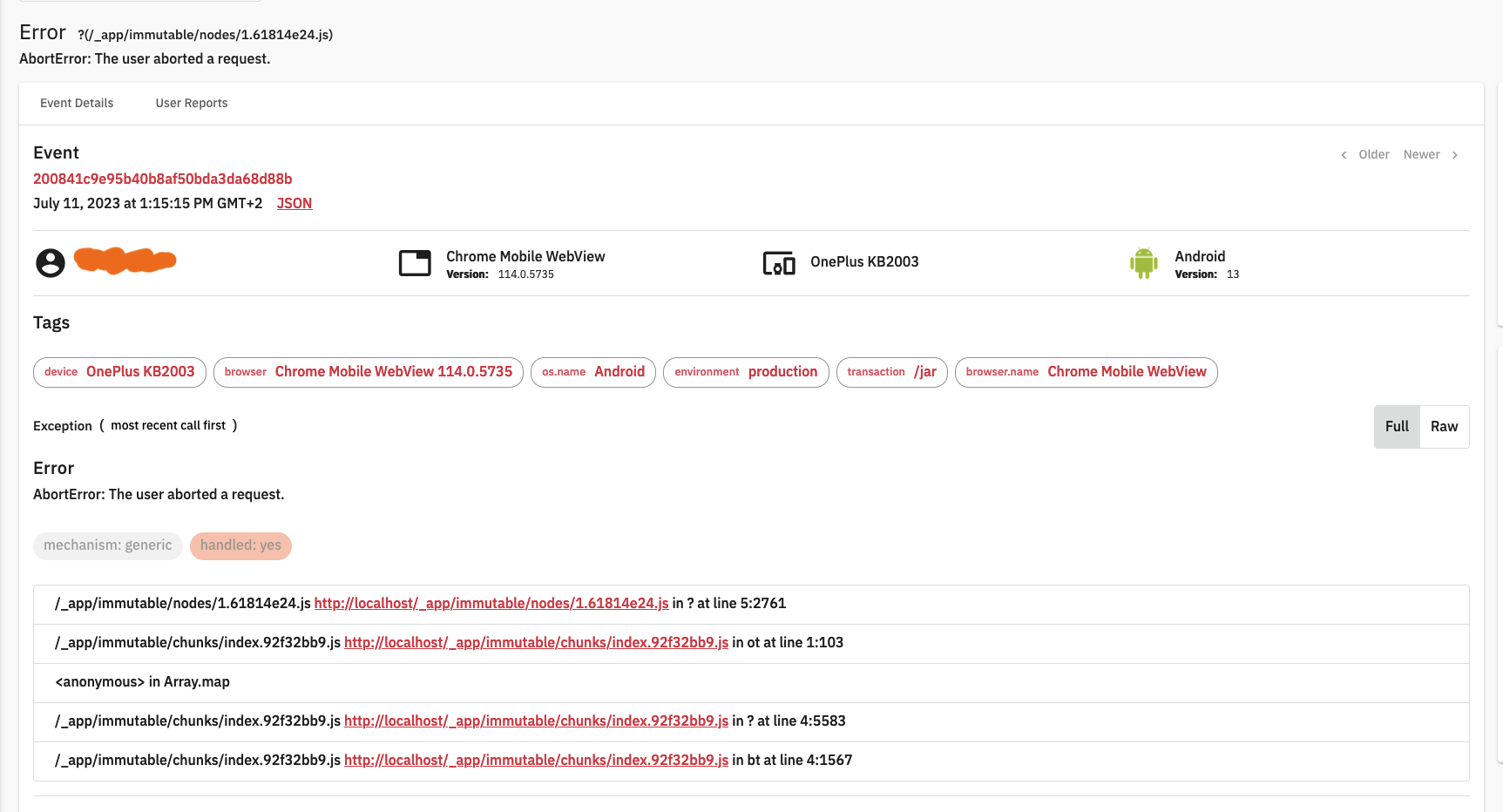
Of course, we first ask our users if they will accept sending of diagnostics data during signup! If consent is not given, we do not initialize the library.

Backups with postgres-backup-local
Many cloud services provide automated backups for your server at a small cost. I mainly rely on this functionality for my server backups. These backups tend to run every couple of days, which is acceptable when restoring a server but preferably you’d want to have a fresh version of the database to restore afterwards. For this I use the prodrigestivill/postgres-backup-local Docker image. You can see an example of the configuration used below:
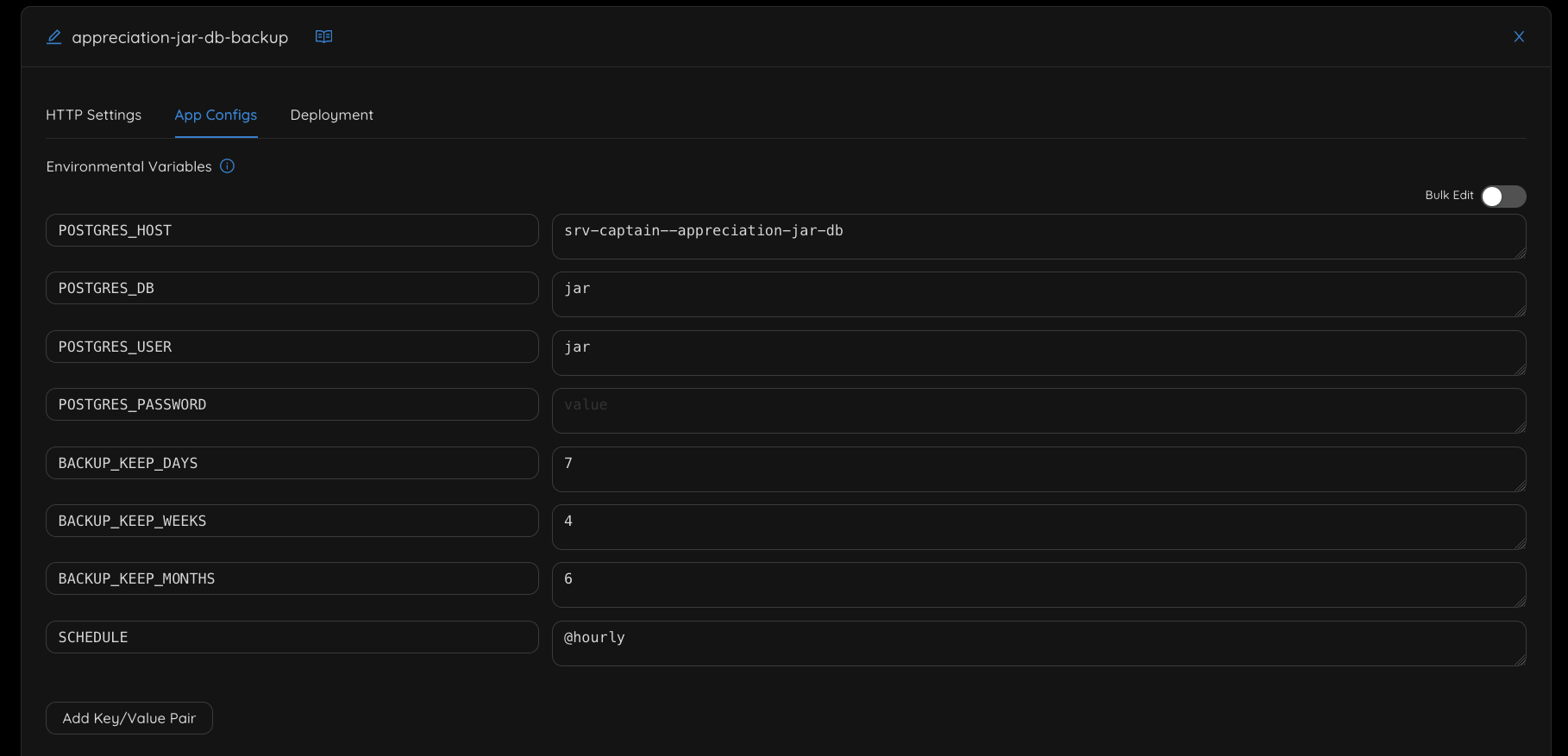
This configuration will place backups of the database every hour in a location on my server. From there I use rsync from my Synology NAS at home to download the backups on a cron schedule.
A note on hosting location
“Location, Location, Location” is a well-known adage, and it works just as well when you’re trying to decide where to host your app.
Unless you’ve lived under a rock for the past few years, it’s impossible to miss the proliferation of serverless cloud services. Vercel, Netlify, Deno Deploy, CloudFlare Workers, Firebase – all the cool kids have a service for you to use. The same goes for cloud databases with offerings like PlanetScale and Supabase – it’s an alluring proposition.
The edge is certainly cool technology, but there are privacy implications to keep in mind. Since edge runtimes run globally, it means that user data can technically be processed anywhere.
If you are from the EU, you are probably aware of the GDPR. While the GDPR is far from perfect, it’s an excellent piece of privacy legislation. It has managed to shift the mindset of most companies from “store as much data as possible” to “data is a liability that should be handled with care”.
Additionally, with the legal invalidation of Privacy Shield which previously permitted transfer of personal data from the EU to US, I don’t think anyone except a laywer can conclusively say whether it’s legally safe to use serverless services if they are working with personal data of EU citizens. My take on this is: if we can build a service that doesn’t require us to deal with complex privacy implications, it sounds like a good idea!
I am currently using DigitalOcean for hosting the app infrastructure on servers running in Germany. DigitalOcean provides a standardised DPA which limits transfers to the US. As DigitalOcean is a US-based company I’m currently also evaluating Hetzner, an EU-based provider.
Conclusion – is this stack too complex?
Some people might read this and come away with the thought “this sure seems like a lot of work for something very simple”. And you’d be right. This architecture is an experiment in self-hosting. You could have gotten away without tracking, error monitoring or realtime. Alternatively you could have used external services that are free or cost just a few dollars per month. But to me, it was worth it to assemble a stack that offers modern features while still being very conscious about user privacy. In the end, every person has to make the trade-off for themselves.
Feel free to leave a comment if you have any questions, and don’t forget to try out Appreciation Jar for Web, iOS and Android!
Social media photo by Federica Galli (@fedechanw) on Unsplash.
View Comments
How I published a gratitude journaling app for iOS and Android using SvelteKit and Capacitor
In this blog post I’d like to share with you how I self-published Appreciation Jar, a...
 Bob
Bob
AuthorThis is exactly what I needed, thank you man